機械と話す未来「第2回 スマートフォンと音声認識」
東北大学
2016/10/04 11:24
第2回 スマートフォンと音声認識
音声認識の普及とスマートフォン(スマホ)は切っても切れない関係にあります。音声認識の研究の歴史は長いのですが、実際には長い間音声認識が広く使われることはありませんでした。
スマホが普及する前、フィーチャーフォン(いわゆるガラケー)には音声認識の機能を持ったものも少なくなかったのですが、その機能を使ったことがある人は多くないのではないでしょうか。
音声認識はたくさんの計算を必要とする、いわゆる「重い」プログラムです。また、認識には音声を収録するためのマイクロフォンが必要ですし、また音声による入力がありがたいような「うまい応用」がないと誰も音声認識を使ってくれません。
そのため、理想的に音声認識をしようとすると、「計算能力が高いコンピュータ」「高性能なマイクロフォン」「音声で入力することがうれしいアプリ」がそろっている必要がありました。これはスマホの出現以前にはあり得ない状況だったのです。
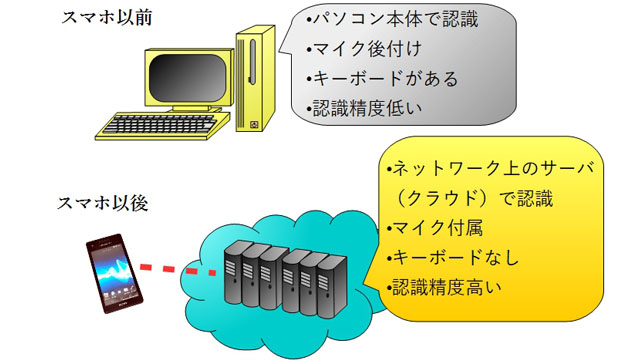
高性能なパソコンにマイクをつないで音声認識をすることは90年代から可能だったのですが、そういうパソコンにはキーボードがついていて、わざわざ音声で入力する必然性がないので、キーボードが使えない事情がある人たち(手に障碍があったり、腱鞘炎でキーが打てないなど)しか利用しませんでした。
ガラケーで音声が認識できればアプリとしては良いのですが、ガラケー自体は計算能力が低く、高性能な音声認識は不可能でした。
スマホの普及によってすべてが変わりました。スマホには高性能なマイクロフォンがついていて、音声入力には問題ありません。またスマホはキーボードを持っていないことが多いので、フリックで入力するよりも手軽であれば音声入力の価値があります。また、スマホの普及と同時に通信回線のスピードが上がったため、音声を通信回線の向こうにある大規模なサーバに送って音声認識をすることが可能になりました。
みなさんがスマホに向かって話しかけたとき、その音声は通信回線を通って、遠く(たとえばアメリカなど)にある大規模なサーバコンピュータで認識されています。その認識結果が再び通信回線を通って手元のスマホに戻ってきているというわけです。話し終わってから認識結果が表示されるまでにほとんど時間遅れを感じないのは、通信と認識処理が高速であるためです。
次回は『第3回 機械との対話』です。
配信日程:10月5日(水)配信予定
【プロフィール】
伊藤 彰則(いとう あきのり)
東北大学大学院工学研究科通信工学専攻教授
ホームページはこちらから
1993年東北大学工学研究科博士課程修了。2010年より現職。音声認識、音声合成、音声対話、音楽情報処理、マルチメディア通信など、声と音を中心に、さまざまなメディアを使った人間と機械のコミュニケーションの研究をしている。
音声認識の普及とスマートフォン(スマホ)は切っても切れない関係にあります。音声認識の研究の歴史は長いのですが、実際には長い間音声認識が広く使われることはありませんでした。
スマホが普及する前、フィーチャーフォン(いわゆるガラケー)には音声認識の機能を持ったものも少なくなかったのですが、その機能を使ったことがある人は多くないのではないでしょうか。
音声認識はたくさんの計算を必要とする、いわゆる「重い」プログラムです。また、認識には音声を収録するためのマイクロフォンが必要ですし、また音声による入力がありがたいような「うまい応用」がないと誰も音声認識を使ってくれません。
そのため、理想的に音声認識をしようとすると、「計算能力が高いコンピュータ」「高性能なマイクロフォン」「音声で入力することがうれしいアプリ」がそろっている必要がありました。これはスマホの出現以前にはあり得ない状況だったのです。
高性能なパソコンにマイクをつないで音声認識をすることは90年代から可能だったのですが、そういうパソコンにはキーボードがついていて、わざわざ音声で入力する必然性がないので、キーボードが使えない事情がある人たち(手に障碍があったり、腱鞘炎でキーが打てないなど)しか利用しませんでした。
ガラケーで音声が認識できればアプリとしては良いのですが、ガラケー自体は計算能力が低く、高性能な音声認識は不可能でした。
スマホの普及によってすべてが変わりました。スマホには高性能なマイクロフォンがついていて、音声入力には問題ありません。またスマホはキーボードを持っていないことが多いので、フリックで入力するよりも手軽であれば音声入力の価値があります。また、スマホの普及と同時に通信回線のスピードが上がったため、音声を通信回線の向こうにある大規模なサーバに送って音声認識をすることが可能になりました。
みなさんがスマホに向かって話しかけたとき、その音声は通信回線を通って、遠く(たとえばアメリカなど)にある大規模なサーバコンピュータで認識されています。その認識結果が再び通信回線を通って手元のスマホに戻ってきているというわけです。話し終わってから認識結果が表示されるまでにほとんど時間遅れを感じないのは、通信と認識処理が高速であるためです。
次回は『第3回 機械との対話』です。
配信日程:10月5日(水)配信予定
【プロフィール】
伊藤 彰則(いとう あきのり)
東北大学大学院工学研究科通信工学専攻教授
ホームページはこちらから
1993年東北大学工学研究科博士課程修了。2010年より現職。音声認識、音声合成、音声対話、音楽情報処理、マルチメディア通信など、声と音を中心に、さまざまなメディアを使った人間と機械のコミュニケーションの研究をしている。