機械と話す未来「第3回 機械との対話」
東北大学
2016/10/05 09:57
第3回 機械との対話
スマホでの音声認識アプリには、音声を使って検索ワードを入力するもの(Google音声検索など)と、音声を使って人間と機械が会話するもの(AppleのSiriや、NTTドコモのしゃべってコンシェル、Yahoo!音声アシスト、Microsoftのコルタナなど)があります。今回は後者の話をしましょう。
検索ワードの入力であれば、声を出した人間が何と言っているのかを知るだけで用が足ります。しかし、会話をするためには、人間が何を言っているのかを知るだけでは不十分で、それに対してどう答えたらよいかを考える必要があります。これを対話管理といいます。対話管理がうまくいかなければ、人間がスマホに向かって「こんにちは」と話しかけたとき、「こんにちは」という単語を検索するようなことが起きます。
対話の管理は、会話内容が比較的限られている場合と、何について会話するかあらかじめ限っておくことができない場合(Siriとの会話など)で異なります。
会話内容が限られている場合とは、たとえば音声による電話自動応答や、限られた内容(たとえば観光のスケジュール作成など)について会話する場合などです。このような場合には、会話の流れをあらかじめ想定しておくことが可能です。
たとえば家電製品のお客様サポートのような場合には、まずどのような用件なのか、対象製品は何なのか、どのようなトラブルがあるのかなどについて利用者に順番に聞いて、その内容に応じて情報を流したり、人間のオペレータにつないだりすることができます。そのため、どういう順番でどういう話をするのかを事前に決め、現在の順番に応じて音声認識結果を解釈して情報を取り出すという方法が使われます。
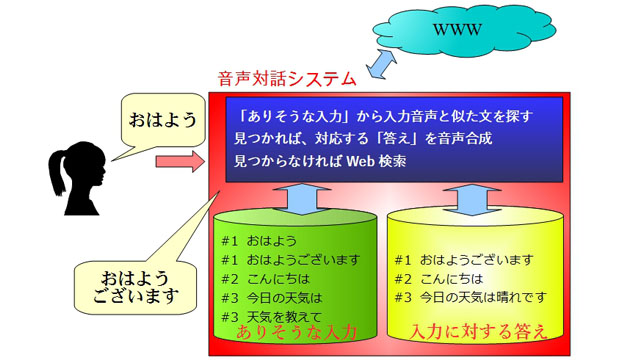
一方、事前にどのような会話をするかわからない場合には、まず「ありそうな入力とその答え」を大量に用意しておき、入力音声がその「ありそうな入力」に合った場合には用意しておいた返答をします。このようにすることで、たとえば「こんにちは」という入力に対してシステムも「こんにちは」と返答することが可能になります。
しかし、これだけでは利用者のすべての入力に答えることはできません。そのため、あらかじめ用意しておいた想定入力に当てはまらない入力がきた場合には、それをそのままWeb検索にかけてしまう方法がよく使われています。Web検索は利用者の意図に沿った答えではありませんが、「当たらずとも遠からず」な情報が出ることが多いため、このようなやり方が使われています。
次回は『第4回 カーナビと音声認識』です。
配信日程:10月6日(木)配信予定
【プロフィール】
伊藤 彰則(いとう あきのり)
東北大学大学院工学研究科通信工学専攻教授
ホームページはこちらから
1993年東北大学工学研究科博士課程修了。2010年より現職。音声認識、音声合成、音声対話、音楽情報処理、マルチメディア通信など、声と音を中心に、さまざまなメディアを使った人間と機械のコミュニケーションの研究をしている。
スマホでの音声認識アプリには、音声を使って検索ワードを入力するもの(Google音声検索など)と、音声を使って人間と機械が会話するもの(AppleのSiriや、NTTドコモのしゃべってコンシェル、Yahoo!音声アシスト、Microsoftのコルタナなど)があります。今回は後者の話をしましょう。
検索ワードの入力であれば、声を出した人間が何と言っているのかを知るだけで用が足ります。しかし、会話をするためには、人間が何を言っているのかを知るだけでは不十分で、それに対してどう答えたらよいかを考える必要があります。これを対話管理といいます。対話管理がうまくいかなければ、人間がスマホに向かって「こんにちは」と話しかけたとき、「こんにちは」という単語を検索するようなことが起きます。
対話の管理は、会話内容が比較的限られている場合と、何について会話するかあらかじめ限っておくことができない場合(Siriとの会話など)で異なります。
会話内容が限られている場合とは、たとえば音声による電話自動応答や、限られた内容(たとえば観光のスケジュール作成など)について会話する場合などです。このような場合には、会話の流れをあらかじめ想定しておくことが可能です。
たとえば家電製品のお客様サポートのような場合には、まずどのような用件なのか、対象製品は何なのか、どのようなトラブルがあるのかなどについて利用者に順番に聞いて、その内容に応じて情報を流したり、人間のオペレータにつないだりすることができます。そのため、どういう順番でどういう話をするのかを事前に決め、現在の順番に応じて音声認識結果を解釈して情報を取り出すという方法が使われます。
一方、事前にどのような会話をするかわからない場合には、まず「ありそうな入力とその答え」を大量に用意しておき、入力音声がその「ありそうな入力」に合った場合には用意しておいた返答をします。このようにすることで、たとえば「こんにちは」という入力に対してシステムも「こんにちは」と返答することが可能になります。
しかし、これだけでは利用者のすべての入力に答えることはできません。そのため、あらかじめ用意しておいた想定入力に当てはまらない入力がきた場合には、それをそのままWeb検索にかけてしまう方法がよく使われています。Web検索は利用者の意図に沿った答えではありませんが、「当たらずとも遠からず」な情報が出ることが多いため、このようなやり方が使われています。
次回は『第4回 カーナビと音声認識』です。
配信日程:10月6日(木)配信予定
【プロフィール】
伊藤 彰則(いとう あきのり)
東北大学大学院工学研究科通信工学専攻教授
ホームページはこちらから
1993年東北大学工学研究科博士課程修了。2010年より現職。音声認識、音声合成、音声対話、音楽情報処理、マルチメディア通信など、声と音を中心に、さまざまなメディアを使った人間と機械のコミュニケーションの研究をしている。