機械と話す未来「第4回 カーナビと音声認識」
東北大学
2016/10/06 09:58
第4回 カーナビと音声認識
カーナビゲーションシステム(カーナビ)は、車を運転するときに大変便利なものです。しかし、車の運転中は運転手は前を見てハンドルを持っていなければならないので、運転中のカーナビ操作には危険が伴います。
そのため、カーナビができた初期の頃から、操作に音声認識を採用するシステムが少なくありません。音声を使えば、カーナビを見ないで、手も使わずにカーナビを操作することが可能です。
しかし、車の中は音声認識にとって大変厳しい環境です。そのために、車の中で高性能な音声認識をするための研究が行われてきており、「車中音声認識」が一つの研究分野になっているほどです。
難しさの最大の要因は、声以外の音、いわゆる「雑音」が多いことです。
車が走っているときには、様々な音がしています。エンジンの音と、タイヤと道路が擦れる音が最も大きい雑音です。それだけでなく、窓を開けていれば風の音がしますし、ラジオやオーディオの音も音声認識にとっては雑音です。同乗者が会話をしていれば、それも雑音になります。
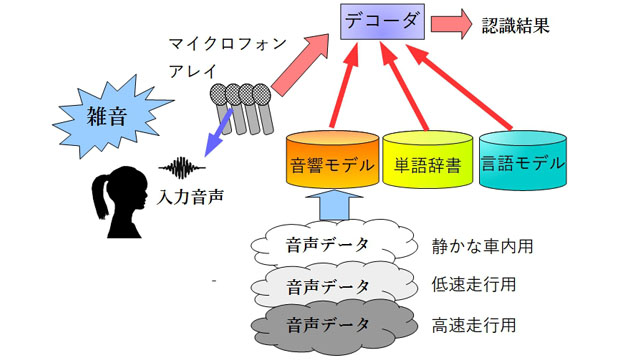
さらに難しいことに、運転者の音声を認識する場合には、口元にマイクロフォンを配置することができません。スマホの場合にはマイクを口元に持ってくれば声を大きく収録することができ、相対的に雑音を小さくすることができるのですが、車の運転者はマイクを持って話すことはできませんし、インカムのようなものをいつもつけて運転するというのも現実的ではありません。結局、離れたところにあるマイクで声を拾う必要があり、そうすると声だけではなく雑音もたくさん拾ってしまうことになります。
これに対する対策は主に二つあります。一つは、できるだけ運転者の声だけを拾ってそれ以外の音を拾わないように、マイクを工夫することです。
これは、たくさんのマイクを並べて、全てのマイクで一斉に声を収録することで可能になります。このようにたくさんのマイクを並べたものをマイクロフォンアレイといって、特定の方向の音だけを収録したり、逆に特定の方向の音だけ消去したりすることが可能です。
運転者の頭がどの辺にあるかは事前に大体わかっていますので、運転者の頭の方向から来る音だけを収録し、それ以外の方向から来る音を収録しないことで、収録された雑音の相対的な大きさを小さくすることができます。
もう一つの対策は、雑音も含めて音響モデルをつくることです。音響モデルは、入力された音が言語の音(「あ」「い」など)のどれに似ているのかを分析するためのモデルですが、入力の声に雑音が混ざると音色が変わるために、分析がうまく行かなくなって認識性能が下がります。
そこで、最初からいろいろな雑音が混ざった音声を使って音響モデルを作っておけば、「アイドリング時の「あ」」「高速走行時の「い」」などを別な音として分析することが可能になります。
このようなさまざまな工夫によって、音声によるカーナビの操作が可能になっているのです。

次回は『第5回 会話する機械の今後』です。
配信日程:10月7日(金)配信予定
【プロフィール】
伊藤 彰則(いとう あきのり)
東北大学大学院工学研究科通信工学専攻教授
ホームページはこちらから
1993年東北大学工学研究科博士課程修了。2010年より現職。音声認識、音声合成、音声対話、音楽情報処理、マルチメディア通信など、声と音を中心に、さまざまなメディアを使った人間と機械のコミュニケーションの研究をしている。
カーナビゲーションシステム(カーナビ)は、車を運転するときに大変便利なものです。しかし、車の運転中は運転手は前を見てハンドルを持っていなければならないので、運転中のカーナビ操作には危険が伴います。
そのため、カーナビができた初期の頃から、操作に音声認識を採用するシステムが少なくありません。音声を使えば、カーナビを見ないで、手も使わずにカーナビを操作することが可能です。
しかし、車の中は音声認識にとって大変厳しい環境です。そのために、車の中で高性能な音声認識をするための研究が行われてきており、「車中音声認識」が一つの研究分野になっているほどです。
難しさの最大の要因は、声以外の音、いわゆる「雑音」が多いことです。
車が走っているときには、様々な音がしています。エンジンの音と、タイヤと道路が擦れる音が最も大きい雑音です。それだけでなく、窓を開けていれば風の音がしますし、ラジオやオーディオの音も音声認識にとっては雑音です。同乗者が会話をしていれば、それも雑音になります。
さらに難しいことに、運転者の音声を認識する場合には、口元にマイクロフォンを配置することができません。スマホの場合にはマイクを口元に持ってくれば声を大きく収録することができ、相対的に雑音を小さくすることができるのですが、車の運転者はマイクを持って話すことはできませんし、インカムのようなものをいつもつけて運転するというのも現実的ではありません。結局、離れたところにあるマイクで声を拾う必要があり、そうすると声だけではなく雑音もたくさん拾ってしまうことになります。
これに対する対策は主に二つあります。一つは、できるだけ運転者の声だけを拾ってそれ以外の音を拾わないように、マイクを工夫することです。
これは、たくさんのマイクを並べて、全てのマイクで一斉に声を収録することで可能になります。このようにたくさんのマイクを並べたものをマイクロフォンアレイといって、特定の方向の音だけを収録したり、逆に特定の方向の音だけ消去したりすることが可能です。
運転者の頭がどの辺にあるかは事前に大体わかっていますので、運転者の頭の方向から来る音だけを収録し、それ以外の方向から来る音を収録しないことで、収録された雑音の相対的な大きさを小さくすることができます。
もう一つの対策は、雑音も含めて音響モデルをつくることです。音響モデルは、入力された音が言語の音(「あ」「い」など)のどれに似ているのかを分析するためのモデルですが、入力の声に雑音が混ざると音色が変わるために、分析がうまく行かなくなって認識性能が下がります。
そこで、最初からいろいろな雑音が混ざった音声を使って音響モデルを作っておけば、「アイドリング時の「あ」」「高速走行時の「い」」などを別な音として分析することが可能になります。
このようなさまざまな工夫によって、音声によるカーナビの操作が可能になっているのです。
次回は『第5回 会話する機械の今後』です。
配信日程:10月7日(金)配信予定
【プロフィール】
伊藤 彰則(いとう あきのり)
東北大学大学院工学研究科通信工学専攻教授
ホームページはこちらから
1993年東北大学工学研究科博士課程修了。2010年より現職。音声認識、音声合成、音声対話、音楽情報処理、マルチメディア通信など、声と音を中心に、さまざまなメディアを使った人間と機械のコミュニケーションの研究をしている。