機械と話す未来「第1回 機械と話す時代」
東北大学
2016/10/03 10:15
第1回 機械と話す時代
機械と人間が会話によって意思疎通をすることは、昔から様々な人たちの「夢」でした。
20世紀にコンピュータが発明されたときに、「コンピュータを使えば、人間と会話する機械ができる」と考えた人は少なくありませんでした。それから60年以上の月日が経ち、ようやく我々の身近なところで「機械と人間とが音声で会話する」という光景が現実のものとなってきました。
機械と人間が会話をする、すなわち音声対話システムを実現するためには、人間の声を機械が聞き取る「音声認識」、機械が人間の声で話す「音声合成」、聞き取った内容に応じて答えを考える「対話管理」の3つの技術が必要です。
これらの技術のもっとも基本的な原理は、もう30年以上前から知られています。それに改良を重ねて、今日の実用的な音声対話システムが実現されています。これらの技術について、簡単に説明したいと思います。
音声認識は、人間の話した言葉を機械が聞き取るための技術です。人間はこれを何の苦もなく行うので、一見簡単そうに思えますが、実は非常に難しく高度な技術です。人間が母語をどうしてこんなに上手に操ることができるのかは十分解明されておらず、現在の音声認識システムはどちらかといえば人間にとっての第二言語習得に似たところがあります。
日本語のみを母語とする人(大部分の日本人)が英語を勉強して自由に聞いたり話したりするのがいかに難しいかを考えれば、機械による音声の認識が簡単でないことがおわかりいただけると思います。
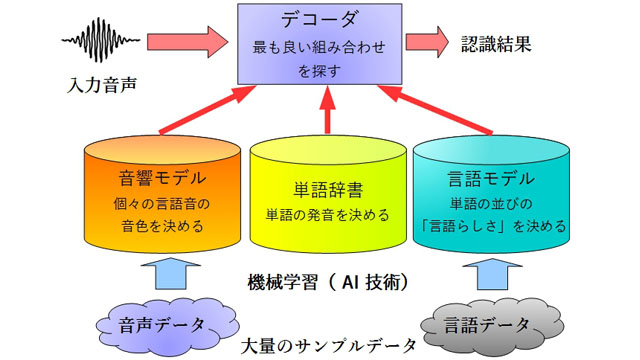
音声の認識には、人間の声の「音としての音色」を表す音響モデル、単語の発音を記述した単語辞書、および言語として妥当な単語の並びを表す言語モデルの3つの要素が必要です。また、これらのモデルを参照して、入力音声にもっともふさわしい認識結果を計算するのが音声認識エンジン(デコーダ)です。
音響モデルは、たとえば「あ」「い」など、単語の元になる音がどういう音色なのかを表現するものです。音響モデルを使うことで、認識したい音声の中の短い区間について、その部分がどんな音でできているのかを分析することができます。これは言うほど簡単ではなく、多くの人の多数の音声(たとえば数百人分の音声1000時間分、など)を分析することでようやく性能の良い音響モデルを作ることができます。
単語辞書は、単語とその発音を集めたものです。実用的なシステムでは、多くの単語(数万~数十万)について辞書を作らなければならないので、作成には多くの労力が必要です。
言語モデルは、単語の並びが言語的に妥当かどうかを表すモデルです。たとえば日本語の場合、「今日 の 天気」という単語の並びは出てきてもおかしくありませんが、「の 天気 今日」という並びはあまり出てきそうにありません。このように、言語モデルを使って単語の並びの「出てきやすさ」を調べたとき、出てきそうな単語の並びには高い得点が、出てきにくそうな単語の並びには低い得点が与えられます。
これらのモデルを使うことで、入力音声が与えられたときに、「各部分の発音が入力音声に似ていて、しかも単語の並びが出てきやすい」という単語列を探すことができます。これを行うのがデコーダです。
音響モデルと言語モデルには機械学習の技術が使われていて、たくさんのサンプルデータを与えると自動的によいモデルをコンピュータが計算してくれます。このような機械学習の技術と、たくさんの単語の組み合わせからもっとも良い組み合わせを探すデコーダの技術は、いずれも最近話題になっている人工知能(AI)の技術と同じものです。
スマートフォンで音声を使った検索をするとき、その背後では非常に大規模なAI技術が動いているのです。
次回は『第2回 スマートフォンと音声認識』です。
配信日程:10月4日(火)配信予定
【プロフィール】
伊藤 彰則(いとう あきのり)
東北大学大学院工学研究科通信工学専攻教授
ホームページはこちらから
1993年東北大学工学研究科博士課程修了。2010年より現職。音声認識、音声合成、音声対話、音楽情報処理、マルチメディア通信など、声と音を中心に、さまざまなメディアを使った人間と機械のコミュニケーションの研究をしている。
機械と人間が会話によって意思疎通をすることは、昔から様々な人たちの「夢」でした。
20世紀にコンピュータが発明されたときに、「コンピュータを使えば、人間と会話する機械ができる」と考えた人は少なくありませんでした。それから60年以上の月日が経ち、ようやく我々の身近なところで「機械と人間とが音声で会話する」という光景が現実のものとなってきました。
機械と人間が会話をする、すなわち音声対話システムを実現するためには、人間の声を機械が聞き取る「音声認識」、機械が人間の声で話す「音声合成」、聞き取った内容に応じて答えを考える「対話管理」の3つの技術が必要です。
これらの技術のもっとも基本的な原理は、もう30年以上前から知られています。それに改良を重ねて、今日の実用的な音声対話システムが実現されています。これらの技術について、簡単に説明したいと思います。
音声認識は、人間の話した言葉を機械が聞き取るための技術です。人間はこれを何の苦もなく行うので、一見簡単そうに思えますが、実は非常に難しく高度な技術です。人間が母語をどうしてこんなに上手に操ることができるのかは十分解明されておらず、現在の音声認識システムはどちらかといえば人間にとっての第二言語習得に似たところがあります。
日本語のみを母語とする人(大部分の日本人)が英語を勉強して自由に聞いたり話したりするのがいかに難しいかを考えれば、機械による音声の認識が簡単でないことがおわかりいただけると思います。
音声の認識には、人間の声の「音としての音色」を表す音響モデル、単語の発音を記述した単語辞書、および言語として妥当な単語の並びを表す言語モデルの3つの要素が必要です。また、これらのモデルを参照して、入力音声にもっともふさわしい認識結果を計算するのが音声認識エンジン(デコーダ)です。
音響モデルは、たとえば「あ」「い」など、単語の元になる音がどういう音色なのかを表現するものです。音響モデルを使うことで、認識したい音声の中の短い区間について、その部分がどんな音でできているのかを分析することができます。これは言うほど簡単ではなく、多くの人の多数の音声(たとえば数百人分の音声1000時間分、など)を分析することでようやく性能の良い音響モデルを作ることができます。
単語辞書は、単語とその発音を集めたものです。実用的なシステムでは、多くの単語(数万~数十万)について辞書を作らなければならないので、作成には多くの労力が必要です。
言語モデルは、単語の並びが言語的に妥当かどうかを表すモデルです。たとえば日本語の場合、「今日 の 天気」という単語の並びは出てきてもおかしくありませんが、「の 天気 今日」という並びはあまり出てきそうにありません。このように、言語モデルを使って単語の並びの「出てきやすさ」を調べたとき、出てきそうな単語の並びには高い得点が、出てきにくそうな単語の並びには低い得点が与えられます。
これらのモデルを使うことで、入力音声が与えられたときに、「各部分の発音が入力音声に似ていて、しかも単語の並びが出てきやすい」という単語列を探すことができます。これを行うのがデコーダです。
音響モデルと言語モデルには機械学習の技術が使われていて、たくさんのサンプルデータを与えると自動的によいモデルをコンピュータが計算してくれます。このような機械学習の技術と、たくさんの単語の組み合わせからもっとも良い組み合わせを探すデコーダの技術は、いずれも最近話題になっている人工知能(AI)の技術と同じものです。
スマートフォンで音声を使った検索をするとき、その背後では非常に大規模なAI技術が動いているのです。
次回は『第2回 スマートフォンと音声認識』です。
配信日程:10月4日(火)配信予定
【プロフィール】
伊藤 彰則(いとう あきのり)
東北大学大学院工学研究科通信工学専攻教授
ホームページはこちらから
1993年東北大学工学研究科博士課程修了。2010年より現職。音声認識、音声合成、音声対話、音楽情報処理、マルチメディア通信など、声と音を中心に、さまざまなメディアを使った人間と機械のコミュニケーションの研究をしている。